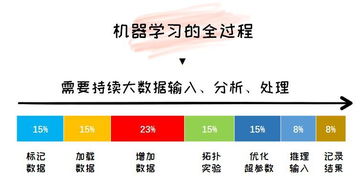
人工智能(AI)正在重塑我們的世界,而神經(jīng)網(wǎng)絡(luò)作為其核心技術(shù),已成為諸多創(chuàng)新應(yīng)用的基石。對(duì)于初學(xué)者而言,選擇Linux操作系統(tǒng)與Python編程語言作為學(xué)習(xí)路徑,不僅能夠降低入門門檻,還能快速掌握構(gòu)建智能軟件的基礎(chǔ)能力。本文將引導(dǎo)你踏上這條高效、實(shí)用的AI入門之旅。
一、 為何選擇Linux與Python?
1. Linux:穩(wěn)定高效的計(jì)算平臺(tái)
Linux系統(tǒng)以其開源、穩(wěn)定、安全和強(qiáng)大的命令行工具著稱,是AI開發(fā)和部署的首選環(huán)境。其核心優(yōu)勢(shì)在于:
- 開源與自由:免費(fèi)獲取,社區(qū)支持強(qiáng)大,擁有海量開源軟件庫。
- 服務(wù)器主導(dǎo)地位:絕大多數(shù)AI模型訓(xùn)練和部署都在Linux服務(wù)器上進(jìn)行,提前熟悉是職業(yè)發(fā)展的必備技能。
- 強(qiáng)大的終端與包管理:通過命令行(如Bash)可以高效管理系統(tǒng)、安裝軟件(使用apt, yum, pip等)和運(yùn)行腳本,自動(dòng)化程度高。
2. Python:AI領(lǐng)域的“通用語”
Python語法簡(jiǎn)潔、易讀,擁有極其豐富且成熟的AI生態(tài)系統(tǒng),是入門和進(jìn)階的不二之選。其關(guān)鍵庫包括:
- NumPy:提供高性能的多維數(shù)組對(duì)象和數(shù)學(xué)函數(shù),是幾乎所有科學(xué)計(jì)算庫的基礎(chǔ)。
- Pandas:用于數(shù)據(jù)清洗、分析和處理的利器。
- Matplotlib/Seaborn:用于數(shù)據(jù)可視化和結(jié)果展示。
- Scikit-learn:經(jīng)典的機(jī)器學(xué)習(xí)算法庫,適合傳統(tǒng)模型入門。
- 核心深度學(xué)習(xí)框架:如TensorFlow、PyTorch、Keras,它們提供了構(gòu)建和訓(xùn)練神經(jīng)網(wǎng)絡(luò)的底層接口和高級(jí)API。
二、 環(huán)境搭建:第一步
- 獲取Linux環(huán)境:
- 新手推薦:在Windows/macOS上安裝WSL2,或使用虛擬機(jī)軟件安裝Ubuntu等發(fā)行版。
- 直接安裝:在電腦上直接安裝Ubuntu作為主系統(tǒng)或雙系統(tǒng)。
- 云服務(wù)器:租用阿里云、騰訊云等提供的云服務(wù)器,直接獲得Linux環(huán)境。
- 配置Python與關(guān)鍵庫:
- Linux通常預(yù)裝Python,但建議使用Anaconda或Miniconda來管理獨(dú)立的Python環(huán)境和包,避免版本沖突。
* 安裝命令示例:
`bash
# 使用pip安裝核心庫
pip install numpy pandas matplotlib scikit-learn
# 安裝深度學(xué)習(xí)框架(以PyTorch為例,請(qǐng)根據(jù)官網(wǎng)命令安裝)
pip install torch torchvision
`
三、 理解神經(jīng)網(wǎng)絡(luò)基礎(chǔ)
在開始編碼前,需要建立基礎(chǔ)認(rèn)知:
- 核心概念:神經(jīng)元、權(quán)重、偏置、激活函數(shù)(如ReLU, Sigmoid)、損失函數(shù)(如均方誤差、交叉熵)、優(yōu)化器(如梯度下降、Adam)。
- 網(wǎng)絡(luò)結(jié)構(gòu):理解輸入層、隱藏層、輸出層。從最簡(jiǎn)單的全連接網(wǎng)絡(luò)開始。
- 學(xué)習(xí)過程:前向傳播計(jì)算預(yù)測(cè)值,反向傳播根據(jù)損失計(jì)算梯度,優(yōu)化器利用梯度更新網(wǎng)絡(luò)參數(shù)。
四、 從零到一:你的第一個(gè)神經(jīng)網(wǎng)絡(luò)程序
以下是一個(gè)使用PyTorch在Linux終端下,構(gòu)建并訓(xùn)練一個(gè)簡(jiǎn)單全連接網(wǎng)絡(luò)識(shí)別手寫數(shù)字(MNIST數(shù)據(jù)集)的極簡(jiǎn)示例:
`python
# 文件名:first_nn.py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
1. 準(zhǔn)備數(shù)據(jù)
transform = transforms.ToTensor()
traindata = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(traindata, batchsize=64, shuffle=True)
2. 定義網(wǎng)絡(luò)模型
class SimpleNN(nn.Module):
def init(self):
super(SimpleNN, self).init()
self.fc1 = nn.Linear(28*28, 128) # 輸入層到隱藏層
self.fc2 = nn.Linear(128, 64) # 隱藏層
self.fc3 = nn.Linear(64, 10) # 隱藏層到輸出層(10個(gè)數(shù)字)
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28*28) # 展平圖片
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x) # 輸出層不需要激活
return x
model = SimpleNN()
3. 定義損失函數(shù)和優(yōu)化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
4. 訓(xùn)練循環(huán)
epochs = 5
for epoch in range(epochs):
runningloss = 0.0
for images, labels in trainloader:
optimizer.zerograd() # 清零梯度
outputs = model(images) # 前向傳播
loss = criterion(outputs, labels) # 計(jì)算損失
loss.backward() # 反向傳播,計(jì)算梯度
optimizer.step() # 更新參數(shù)
runningloss += loss.item()
print(f'Epoch {epoch+1}, Loss: {runningloss/len(trainloader):.4f}')
print("訓(xùn)練完成!")
# 保存模型
torch.save(model.statedict(), 'simplemnist_model.pth')
`
在Linux終端中運(yùn)行:`bash
python first_nn.py`
五、 邁向人工智能基礎(chǔ)軟件開發(fā)
完成基礎(chǔ)模型構(gòu)建后,你可以向更完整的“軟件”邁進(jìn):
- 模塊化與工程化:將數(shù)據(jù)加載、模型定義、訓(xùn)練、評(píng)估等邏輯拆分成獨(dú)立的模塊(
.py文件),提高代碼可讀性和復(fù)用性。 - 模型保存與加載:使用
torch.save和torch.load保存訓(xùn)練好的模型,以便后續(xù)部署或繼續(xù)訓(xùn)練。 - 構(gòu)建預(yù)測(cè)接口:編寫一個(gè)函數(shù)或簡(jiǎn)單的腳本,加載已保存的模型,接受新的輸入數(shù)據(jù)(如圖片),并返回預(yù)測(cè)結(jié)果。
- 開發(fā)簡(jiǎn)單應(yīng)用:
- 命令行工具:使用
argparse庫創(chuàng)建帶參數(shù)的命令行程序,用于訓(xùn)練或預(yù)測(cè)。
- Web API服務(wù):使用Flask或FastAPI框架,將你的模型封裝成RESTful API,供其他程序調(diào)用。
- 圖形界面:使用Tkinter、PyQt或Gradio快速構(gòu)建一個(gè)帶有圖形界面的演示程序。
- 版本控制:使用Git管理你的代碼,是軟件開發(fā)的基本功。
六、 后續(xù)學(xué)習(xí)路徑建議
- 深入理論:系統(tǒng)學(xué)習(xí)線性代數(shù)、概率論、微積分和機(jī)器學(xué)習(xí)課程。
- 掌握框架:精通PyTorch或TensorFlow其中之一,理解其自動(dòng)微分、計(jì)算圖等核心機(jī)制。
- 學(xué)習(xí)經(jīng)典網(wǎng)絡(luò):從CNN(處理圖像)、RNN/LSTM(處理序列)開始,理解其結(jié)構(gòu)與應(yīng)用場(chǎng)景。
- 實(shí)踐項(xiàng)目:在Kaggle等平臺(tái)參與競(jìng)賽,或復(fù)現(xiàn)經(jīng)典論文,解決真實(shí)問題。
- 探索部署:了解如何使用Docker容器化你的應(yīng)用,或使用ONNX、TensorRT等工具進(jìn)行模型優(yōu)化和部署到生產(chǎn)環(huán)境。
以Linux為舟,Python為槳,神經(jīng)網(wǎng)絡(luò)為帆,你已站在人工智能浩瀚海洋的入海口。這條路徑強(qiáng)調(diào)實(shí)踐與理論結(jié)合,從在終端中運(yùn)行第一行代碼開始,逐步構(gòu)建出可用的智能軟件組件。記住,持續(xù)編碼、閱讀優(yōu)秀代碼和參與社區(qū)是成長(zhǎng)的最佳催化劑。現(xiàn)在,打開你的終端,開始創(chuàng)造吧!